Writing Scripts and Submitting Jobs to Katana
Overview
Questions
How can we automate a commonly used set of commands?
How can we submit a job to the HPC?
Objectives
Use the
vimtext editor to modify text files.Write a basic shell script.
Use
qsubto run a job interactively.Use the
bashcommand to execute a shell script.Use
chmodto make a script an executable program.
Writing files
We’ve been able to do a lot of work with files that already exist, but what if we want to write our own files? We’re not going to type in a FASTA file, but we’ll see as we go through other tutorials, there are a lot of reasons we’ll want to write a file, or edit an existing file.
To add text to files, we’re going to use a text editor called vim. We’re going to create a file to take notes about what we’ve been doing with the data files in data.
This is good practice when working in bioinformatics. We can create a file called README.txt that describes the data files in the directory or documents how the files in that directory were generated. As the name suggests, it’s a file that we or others should read to understand the information in that directory.
Let’s change our working directory to data using cd, then run vim to create a file called README.txt:
$ cd data
$ vim README.txt
You should see something like this:
The text at the bottom of the screen shows the keyboard shortcuts for performing various tasks in vim. We will talk more about how to interpret this information soon.
Which Editor?
When we say, “
vimis a text editor. On Unix systems (such as Linux and Mac OS X), many programmers use Emacs or Vim (both of which require more time to learn), or a graphical editor such as Gedit. On Windows, you may wish to use Notepad++. Windows also has a built-in editor callednotepadthat can be run from the command line in the same way asnanofor the purposes of this lesson.
Now you’ve written a file. You can take a look at it with less or cat, or open it up again and edit it with vim.
Exercise
Open
README.txtand add the date to the top of the file and save the file.
Katana - How to start an interative job
For a more in depth understanding of Katana (https://unsw-restech.github.io/using_katana/). We will not be going into a deep dive of high performance computers. In essence, compute nodes are just high performance computers. Made up of multiple fast CPUs (computational processing units), extra RAM (random access memory) and you can request whatever your analysis requires
The head node is not particularly powerful, and is shared by all logged-in users. Never run computational intense jobs there!!
Different clusters use use different tools to manage resources and schedule jobs. Katana uses OpenPBS to control access to compute nodes.
The “polite” thing to do is to request an interactive node, or submit a job. For small jobs that you are troubleshooting, form an interactive session. An interactive job or interactive session is a session on a compute node with the required physical resources for the period of time requested. To request an interactive job, add the -I flag (capital i) to qsub. Default sessions will have 1 CPU core, 1GB and 1 hour
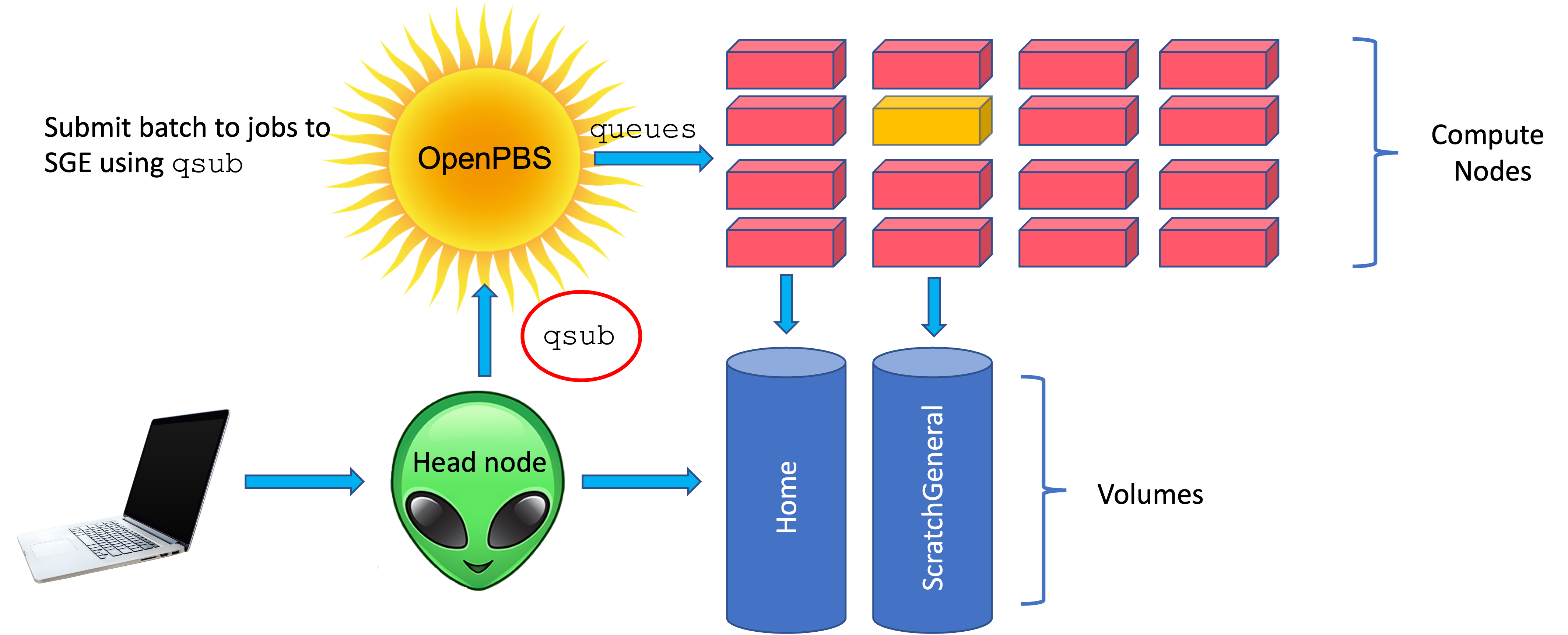
For example, the following two commands. The first provides a default session, the second provides a session with two CPU core and 8GB memory for three hours. You can tell when an interactive job has started when you see the name of the server change from katana1 or katana2 to the name of the server your job is running on. In these cases it’s k181 and k201 respectively.
$ qsub -I
qsub: waiting for job 313704.kman.restech.unsw.edu.au to start
qsub: job 313704.kman.restech.unsw.edu.au ready
$ qsub -I -l select=1:ncpus=2:mem=8gb,walltime=3:00:00
qsub: waiting for job 1234.kman.restech.unsw.edu.au to start
qsub: job 1234.kman.restech.unsw.edu.au ready
Jobs are constrained by the resources that are requested. In the previous example the first job - running on k181 - would be terminated after 1 hour or if a command within the session consumed more than 8GB memory. The job (and therefore the session) can also be terminated by the user with CTRL-D or the logout command.
Writing scripts
A really powerful thing about the command line is that you can write scripts. Scripts let you save commands to run them and also lets you put multiple commands together. Though writing scripts may require an additional time investment initially, this can save you time as you run them repeatedly. Scripts can also address the challenge of reproducibility: if you need to repeat an analysis, you retain a record of your command history within the script.
One thing we will commonly want to do with sequencing results is pull out bad reads and write them to a file to see if we can figure out what’s going on with them. We’re going to look for reads with long sequences of N’s like we did before, but now we’re going to write a script, so we can run it each time we get new sequences, rather than type the code in by hand each time.
We’re going to create a new file to put this command in. We’ll call it bad-reads-script.sh. The sh isn’t required, but using that extension tells us that it’s a shell script.
$ vim bad-reads-script.sh
Bad reads have a lot of N’s, so we’re going to look for NNNNNNNNNN with grep. We want the whole FASTQ record, so we’re also going to get the one line above the sequence and the two lines below. We also want to look in all the files that end with .fastq, so we’re going to use the * wildcard.
grep -B1 -A2 -h NNNNNNNNNN *.fastq | grep -v '^--' > scripted_bad_reads.txt
Custom
grepcontrolWe introduced the
-voption previously, now we are using-hto “Suppress the prefixing of file names on output” according to the documentation shown byman grep.
Type your grep command into the file and save it as before. Be careful that you did not add the $ at the beginning of the line.
Now comes the neat part. We can run this script. Type:
$ bash bad-reads-script.sh
It will look like nothing happened, but now if you look at scripted_bad_reads.txt, you can see that there are now reads in the file.
Exercise
We want the script to tell us when it’s done.
- Open
bad-reads-script.shand add the lineecho "Script finished!"after thegrepcommand and save the file.- Run the updated script.
Making the script into a program
We had to type bash because we needed to tell the computer what program to use to run this script. Instead, we can turn this script into its own program. We need to tell the computer that this script is a program by making the script file executable. We can do this by changing the file permissions.
First, let’s look at the current permissions.
$ ls -l bad-reads-script.sh
We see that it says -rw-r--r--. This shows that the file can be read by any user and written to by the file owner (you). We want to change these permissions so that the file can be executed as a program. We use the command chmod like we did earlier when we removed write permissions. Here we are adding (+) executable permissions (+x).
$ chmod +x bad-reads-script.sh
Now let’s look at the permissions again.
$ ls -l bad-reads-script.sh
-rwxrwxr-x 1 helkin helkin 0 Oct 25 21:46 bad-reads-script.sh
Now we see that it says -rwxr-xr-x. The x’s that are there now tell us we can run it as a program. So, let’s try it! We’ll need to put ./ at the beginning so the computer knows to look here in this directory for the program.
$ ./bad-reads-script.sh
The script should run the same way as before, but now we’ve created our very own computer program!
Katana - How to start an batch job
A batch job is a script that runs autonomously on a compute node. The script must contain the necessary sequence of commands to complete a task independently of any input from the user. This section contains information about how to create and submit a batch job on Katana.
You must now edit your bad-reads-script.sh to have the same format as below.
#!/bin/bash
grep -B1 -A2 -h NNNNNNNNNN *.fastq | grep -v '^--'
This script can be now be submitted to the cluster with qsub and it will become a job and be assigned to a queue.
$ qsub ./bad-reads-script.sh
As with interactive jobs, the -l (lowercase L) flag can be used to specify resource requirements for the job:
$ qsub -l select=1:ncpus=1:mem=4gb,walltime=12:00:00 ./bad-reads-script.sh
You can also rewrite your original script to include the job requests within the script like below:
#!/bin/bash
#PBS -l select=1:ncpus=1:mem=4gb
#PBS -l walltime=12:00:00
grep -B1 -A2 -h NNNNNNNNNN *.fastq | grep -v '^--'
Transferring Data Between your Local Machine and Katana (there and back again)
Uploading Data to your Virtual Machine with scp
scp stands for ‘secure copy protocol’, and is a widely used UNIX tool for moving files between computers. The simplest way to use scp is to run it in your local terminal, and use it to copy a single file:
scp <file I want to move> <where I want to move it>
Note that you are always running scp locally, but that doesn’t mean that you can only move files from your local computer. In order to move a file from your local computer to an AWS instance, the command would look like this:
$ scp <local file> <katana login details>:"location"
e.g On my Mac computer* scp README.md zID@katana.restech.unsw.edu.au:”somewhere/nice/”
To move it back to your local computer, you re-order the to and from fields:
$ scp <katana login details> <local file>:"location"
e.g On my Mac computer* scp zID@katana.restech.unsw.edu.au:”somewhere/nice/README.md” /somewhere/okay/
Tip: If you are looking for another (or any really) text file in your home directory to use instead, try:
$ find ~ -name *.txt
Key Points
Scripts are a collection of commands executed together.
How to submit interactive jobs
Transferring information to and from virtual and local computers.
Adapted from the Data Carpentry Intro to Command Line -shell genomics https://datacarpentry.org/shell-genomics/
Licensed under CC-BY 4.0 2018–2021 by The Carpentries
Licensed under CC-BY 4.0 2016–2018 by Data Carpentry